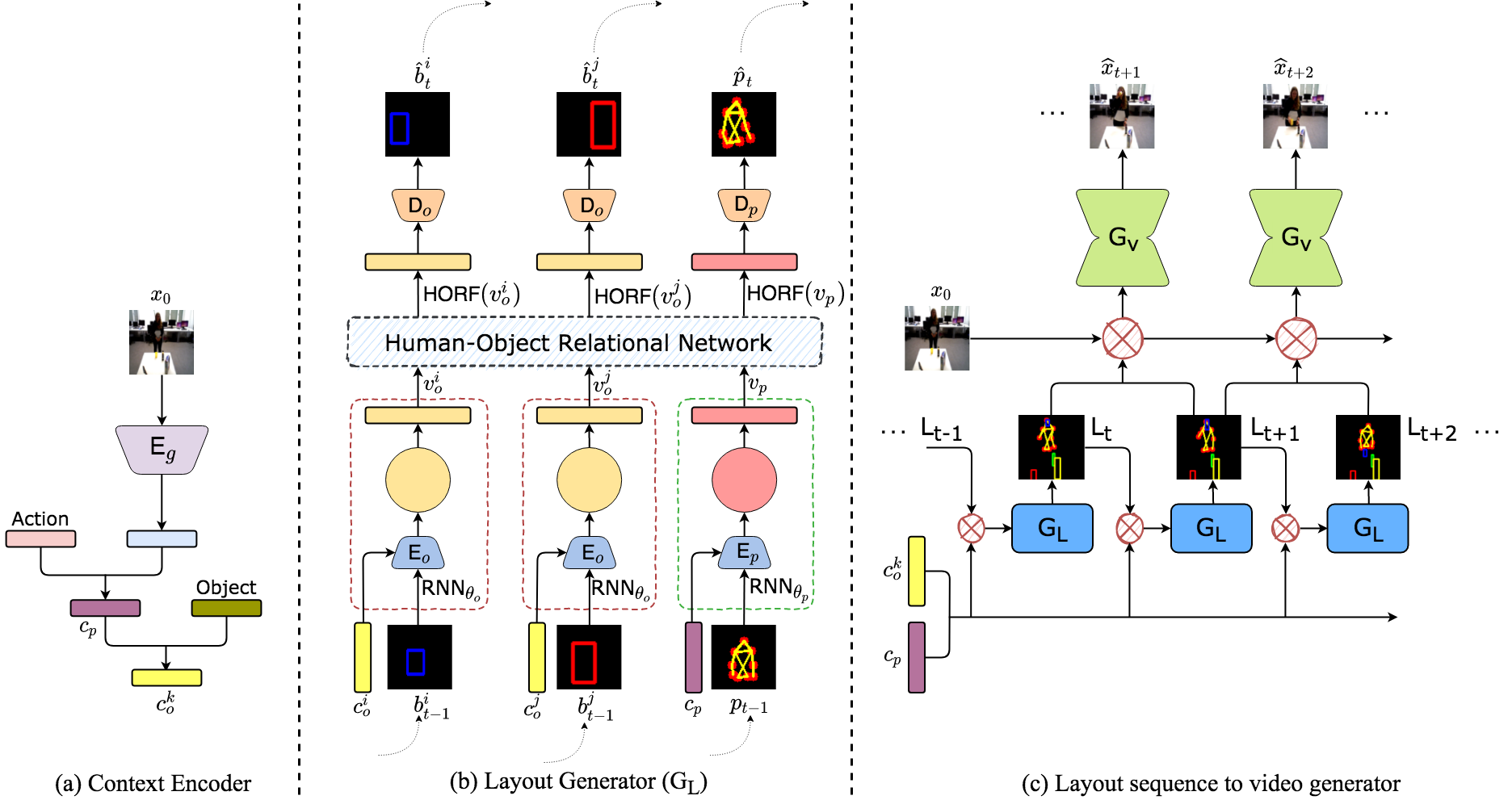
Learning to model and predict how humans interact with objects while performing an action is challenging, and most of the existing video prediction models are ineffective in modeling complicated human-object interactions. Our work builds on hierarchical video prediction models, which disentangle the video generation process into two stages: predicting a high-level representation, such as pose sequence, and then learning a pose-to-pixels translation model for pixel generation. An action sequence for a human-object interaction task is typically very complicated, involving the evolution of pose, person’s appearance, object locations, and object appearances over time. To this end, we propose a Hierarchical Video Prediction model using Relational Layouts. In the first stage, we learn to predict a sequence of layouts. A layout is a high-level representation of the video containing both pose and objects’ information for every frame. The layout sequence is learned by modeling the relationships between the pose and objects using relational reasoning and recurrent neural networks. The layout sequence acts as a strong structure prior to the second stage that learns to map the layouts into pixel space. Experimental evaluation of our method on two datasets, UMD-HOI and Bimanual, shows significant improvements in standard video evaluation metrics such as LPIPS, PSNR, and SSIM. We also perform a detailed qualitative analysis of our model to demonstrate various generalizations.
Shown below are the videos generated by our model on the Bimanual dataset for the various cooking actions and workshop actions.






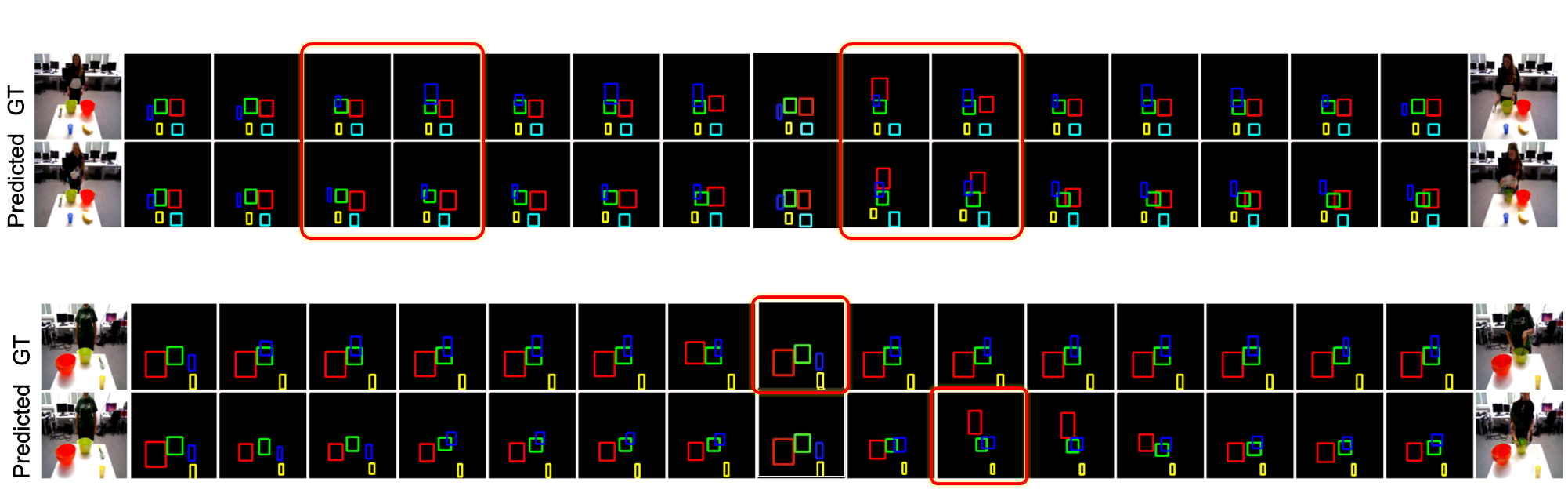
Below are qualitative results of bounding box prediction from our model. First row is ground truth sequence and second row is predicted sequence from our model. Observe that our model is able to faithfully capture the spatial relations among various objects. In the second example below, we observe that the predicted video has a phase shift of few frames, which indicates that the model is able predict these sequences with different speeds.
Below are a few generalization results of our model.

@InProceedings{Bodla_2021_CVPR,
author = {Bodla, Navaneeth and Shrivastava, Gaurav and Chellappa, Rama and Shrivastava, Abhinav},
title = {Hierarchical Video Prediction Using Relational Layouts for Human-Object Interactions},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {12146-12155}
}